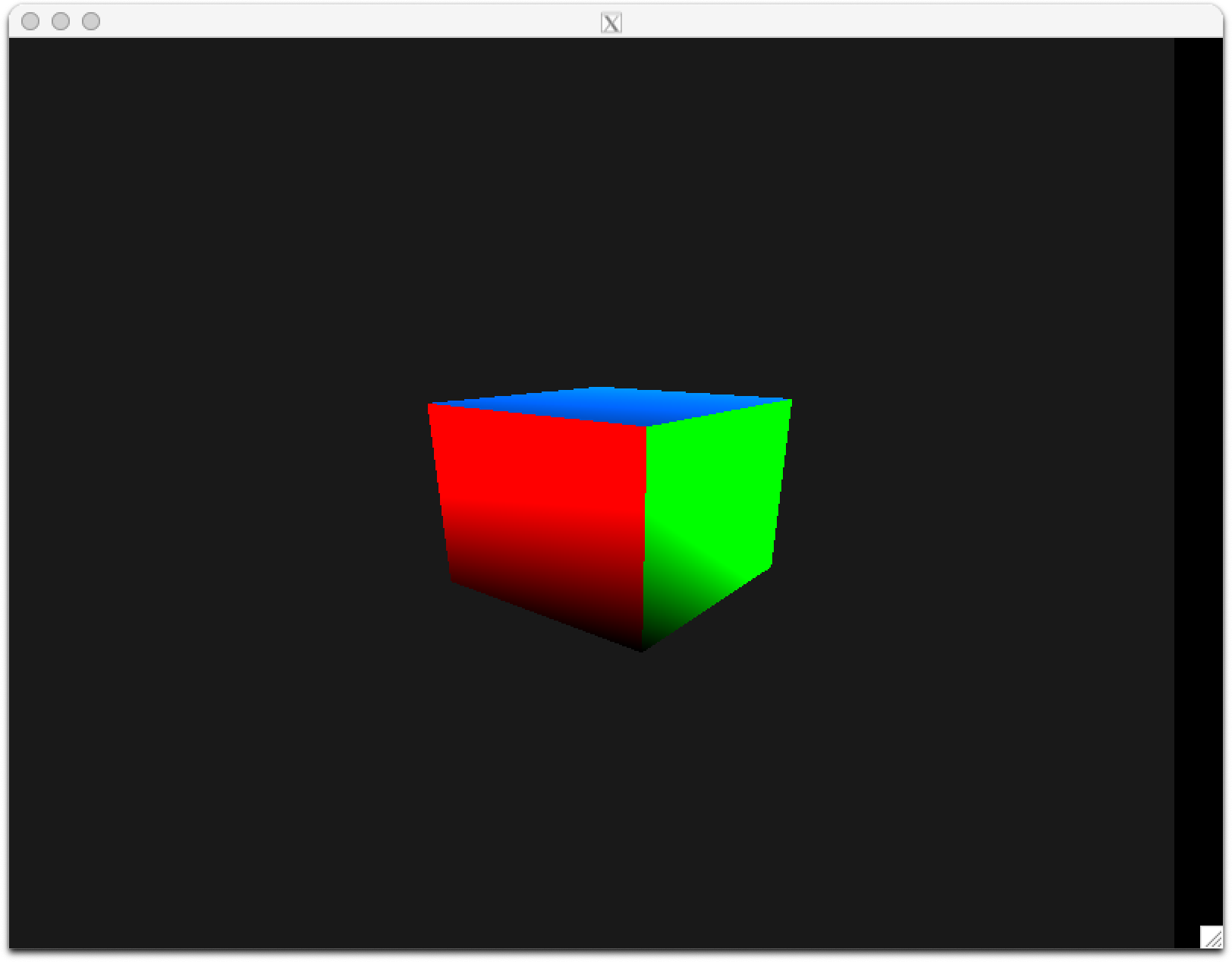
18 Apr 2021
After a few weeks of investigating the Apple M1 GPU in January, I was able to draw a triangle with my own open source code. Although I began dissecting the instruction set, the shaders there were specified as machine code. A real graphics driver needs a compiler from high-level shading languages (GLSL or Metal) to a native binary. Our understanding of the M1 GPU’s instruction set has advanced over the past few months. Last week, I began writing a free and open source shader compiler targeting the Apple GPU. Progress has been rapid: at the end of its first week, it can compile both basic vertex and fragment shaders, sufficient to render 3D scenes. The spinning cube pictured above has its shaders written in idiomatic GLSL, compiled with the nascent free software compiler, and rendered with native code like the first triangle in January. No proprietary blobs here!
Over the past few months, Dougall Johnson has investigated the instruction set in-depth, building on my initial work. His findings on the architecture are outstanding, focusing on compute kernels to complement my focus on graphics. Armed with his notes and my command stream tooling, I could chip away at a compiler.
The compiler’s design must fit into the development context. Asahi Linux aims to run a Linux desktop on Apple Silicon, so our driver should follow Linux’s best practices like upstream development. That includes using the New Intermediate Representation (NIR) in Mesa, the home for open source graphics drivers. NIR is a lightweight library for shader compilers, with a GLSL frontend and backend targets including Intel and AMD. NIR is an alternative to LLVM, the compiler framework used by Apple. Just because Apple prefers LLVM doesn’t mean we have to. A team at Valve famously rewrote AMD’s LLVM backend as a NIR compiler, improving performance. If it’s good enough for Valve, it’s good enough for me.
Supporting NIR as input does not dictate our compiler’s own intermediate representation, which reflects the hardware’s design. The instruction set of AGX2 (Apple’s GPU) has:
Each hardware property induces a compiler property:
Putting it together, a design for an AGX compiler emerges: a code generator translating NIR to an SSA-based intermediate representation, optimized by instruction combining passes, scheduled to minimize register pressure, register allocated while going out of SSA, scheduled again to maximize instruction-level parallelism, and finally packed to binary instructions.
These decisions reflect the hardware traits visible to software,
which are themselves “shadows” cast by the hardware design.
Investigating these traits offers insight into the hardware itself.
Consider the register file. While every thread can access up to 256
half-word registers, there is a performance penalty: the more registers
used, the fewer concurrent threads possible, since threads share a
register file. The number of threads allowed in a given shader is
reported in Metal as the maxTotalThreadsPerThreadgroup
property. So, we can study the register pressure versus occupancy
trade-off by varying the register pressure of Metal shaders (confirmed
via our disassembler) and correlating with the value of
maxTotalThreadsPerThreadgroup:
| Registers | Threads |
|---|---|
| <= 104 | 1024 |
| 112 | 896 |
| 120, 128 | 832 |
| 136 | 768 |
| 144 | 704 |
| 152, 160 | 640 |
| 168-184 | 576 |
| 192-208 | 512 |
| 216-232 | 448 |
| 240-256 | 384 |
From the table, it’s clear that up until a threshold, it doesn’t matter how many registers the program uses; occupancy is unaffected. Most well-written shaders fall in this bracket and need not worry. After hitting the threshold, other GPUs might spill registers to memory, but Apple doesn’t need to spill until more than 256 registers are required. Between 112 and 256 registers, the number of threads decreases in an almost linear fashion, in increments of 64 threads. Carefully considering rounding, it’s easy to recover the formula Metal uses to map register usage to thread count.
What’s less obvious is that we can infer the size of the machine’s register file. On one hand, if 256 registers are used, the machine can still support 384 threads, so the register file must be at least 256 half-words * 2 bytes per half-word * 384 threads = 192 KiB large. Likewise, to support 1024 threads at 104 registers requires at least 104 * 2 * 1024 = 208 KiB. If the file were any bigger, we would expect more threads to be possible at higher pressure, so we guess each threadgroup has exactly 208 KiB in its register file.
The story does not end there. From Apple’s public specifications, the M1 GPU supports 24576 = 1024 * 24 simultaneous threads. Since the table shows a maximum of 1024 threads per threadgroup, we infer 24 threadgroups may execute in parallel across the chip, each with its own register file. Putting it together, the GPU has 208 KiB * 24 = 4.875 MiB of register file! This size puts it in league with desktop GPUs.
For all the visible hardware features, it’s equally important to consider what hardware features are absent. Intriguingly, the GPU lacks some fixed-function graphics hardware ubiquitous among competitors. For example, I have not encountered hardware for reading vertex attributes or uniform buffer objects. The OpenGL and Vulkan specifications assume dedicated hardware for each, so what’s the catch?
Simply put – Apple doesn’t need to care about Vulkan or OpenGL performance. Their only properly supported API is their own Metal, which they may shape to fit the hardware rather than contorting the hardware to match the API. Indeed, Metal de-emphasizes vertex attributes and uniform buffers, favouring general constant buffers, a compute-focused design. The compiler is responsible for translating the fixed-function attribute and uniform state to shader code. In theory, this has a slight runtime cost; conventional wisdom says dedicated hardware is faster and lower power than software emulation. In practice, the code is so simple it may make no difference, although application developers should be mindful of the vertex formats used in case conversion code is inserted. As always, there is a trade-off: omitting features allows Apple to squeeze more arithmetic logic units (or register file!) onto the chip, speeding up everything else.
The more significant concern is the increased time on the CPU spent compiling shaders. If changing fixed-function attribute state can affect the shader, the compiler could be invoked at inopportune times during random OpenGL calls. Here, Apple has another trick: Metal requires the layout of vertex attributes to be specified when the pipeline is created, allowing the compiler to specialize formats at no additional cost. The OpenGL driver pays the price of the design decision; Metal is exempt from shader recompile tax.
The silver lining is that there is nothing to reverse-engineer for “missing” features like attributes and uniform buffers. As long as we know how to access memory in compute kernels, we can write the lowering code ourselves with no hardware mysteries. So far, I’ve implemented enough to spin a cube.
At present, the in-progress compiler supports most arithmetic and input/output instructions found in OpenGL ES 2.0, with a simple optimizer and native instruction packing. Support for control flow, textures, scheduling, and register allocation will come further down the line as we work towards a real driver.